ledsun.hatenablog.com
なるほど、これは素敵なアンサー記事。実際にどうやってOSSから学びを得るか、分かりやすい。
しかし、そうなると元々PerlのCPANから学んだ、と書いた手前、CPAN & Perl編を書かない訳にはいかない。
ほかの言語用は誰か書いてください!!!!
例えばHTMLエスケープの実装が知りたいとき
元の記事と同じようにPerlでHTMLをエスケープしたいけど、どう実装したら漏れなく対応できるかわからない状況を仮定しましょう。
Perlのモジュールリポジトリといえば、おなじみCPAN(Comprehensive Perl Archive Network)です。
やはり元の記事と同じように、雑にhtmlとescapeで検索してみます。
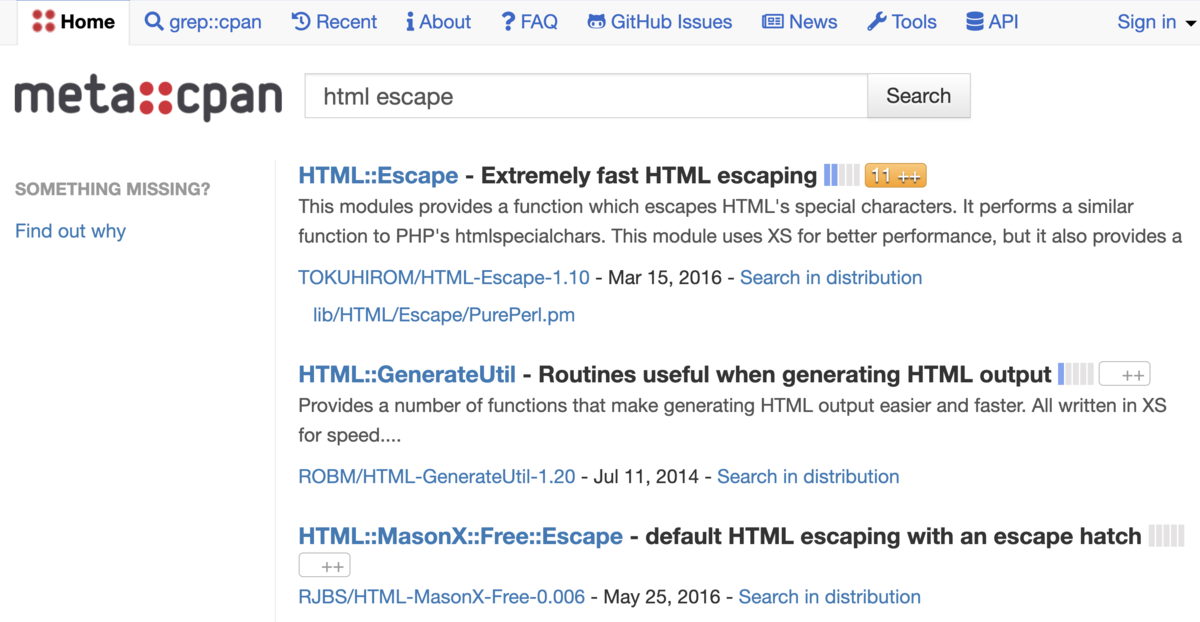
検索結果の最上位は、HTML::Escape - Extremely fast HTML escapingと出ています。名前も分かりやすいし、「極めて速い」という説明からも良さそうですね。
モジュール名の右側に有るメーターは、どれだけ他のモジュールから利用されているかを示しています。その横の数値は、所謂「いいね」の数です。
ざっと他のモジュールよりも評価が高そうです。早速、このモジュールを見てみることにしましょう(やはりnpmに比べると同じようなモジュールが出てくる率が低いですね)。
metacpan.org
先程の検索結果の左側に、リポジトリへのリンクもあります。そこからたどりましょう。
https://github.com/tokuhirom/HTML-Escape
Perlのモジュールは、モジュールのディストリビューションのハイフンをスラッシュに置き換えてパスを作り、最初の単語の前にlib/をくっ付け、最後の単語の後ろに.pmをくっ付けると、エントリポイントが得られます。つまり、lib/HTML/Escape.pmがこのモジュールのエントリポイントになります。
あ、いきなりモジュールの中身を見る前に、ドキュメントはしっかり見ておきましょう。先程の検索結果のHTML::Escapeの部分をクリックするとドキュメントを参照できます。
https://metacpan.org/pod/HTML::Escape
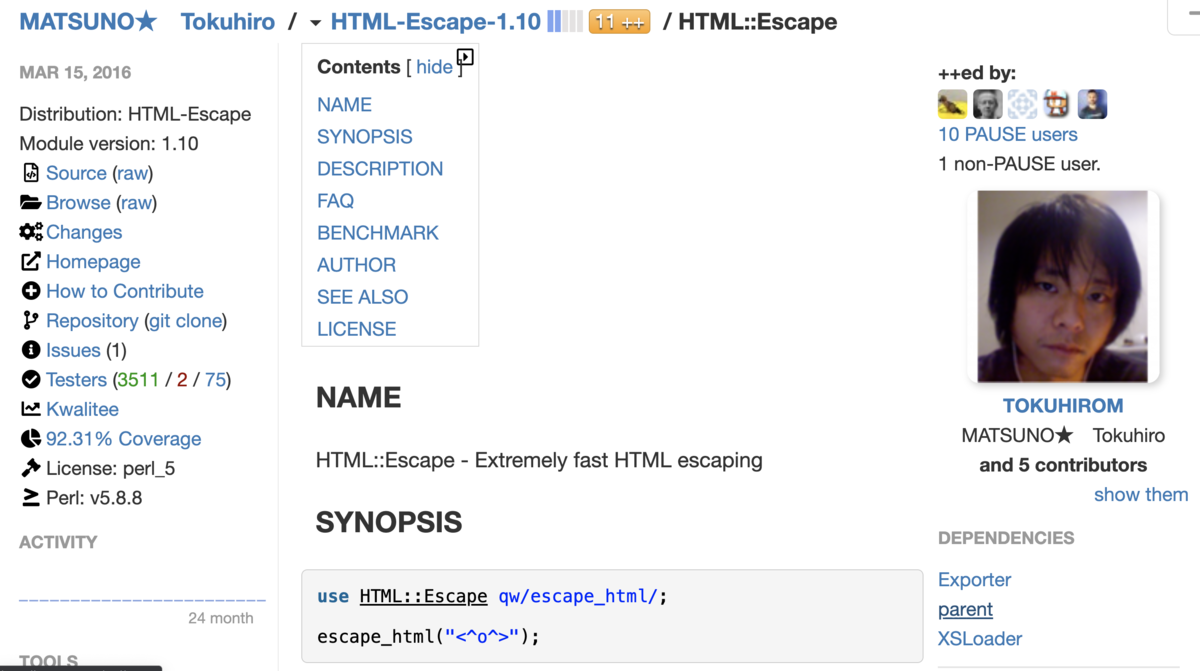
ここがCPANの最高なところなのですが…「モジュールの作者名が一番最初に表示されている」「作者にアイコンが大きく表示されている」…作った人の顔が見えるのがCPANのいいところ。このモジュールは、Perlで数々の素晴らしいモジュールをリリースされているTOKUHIROMさんの作であることが分かります。
また、Perlのドキュメントはフォーマットが決まっていて、例えば、モジュール名の次は、必ずSYNOPSISです。これを見れば、一番基本的な使い方がすぐに分かるように工夫されています。
use HTML::Escape qw/escape_html/;
escape_html("<^o^>");
とっても分かりやすいですね(ちなみにエスケープの結果は、<^o^>になります)。
さて、使い方が分かったところで実装を見てみましょう。
escape関数の実装を読む
エントリポイントとなるlib/HTML/escape.pmは、ドキュメントを除くとわずか28行のモジュールです。
https://github.com/tokuhirom/HTML-Escape/blob/master/lib/HTML/Escape.pm
コードの箇所を抜き出してみました。
package HTML::Escape;
use strict;
use warnings;
use 5.008005;
our $VERSION = '1.10';
use parent qw/Exporter/;
my $use_xs = 0;
if(!exists $INC{'HTML/Escape/PurePerl.pm'}) {
my $pp = $ENV{PERL_ONLY};
if (!$pp) {
eval {
require XSLoader;
XSLoader::load(__PACKAGE__, $VERSION);
$use_xs = 1;
};
}
if (!__PACKAGE__->can('escape_html')) {
require 'HTML/Escape/PurePerl.pm'
}
}
sub USE_XS () { $use_xs }
our @EXPORT = qw/escape_html/;
至るところにxs、XSというキーワードが出てきます。XSとは、PerlのC言語拡張のためのインタフェース記述言語で、この機能によりC言語で書かれたコードをPerlから呼び出すことができるようになります。
また、'HTML/Escape/PurePerl.pm'というパスが有ることも分かると思います。これは名前の通り、Perlのみで実装されたHTML::Escapeの実装です。
Perlのモジュールには、Cコンパイラが使える環境であればXS経由でC言語で実装された高速バージョンが、何らかの理由でCコンパイラが使えない環境であれば(比較すると低速な)Pure Perlバージョンがインストールされるものが多数存在します。現代では、あまりCコンパイラの環境制約が有ることは少ないと思いますが、この仕組みによりレンタルサーバのようにCコンパイラが使えない環境でもモジュールがインストールできる、というわけです。
しかも、このように同じ仕様に対して二つの実装が用意されることで、一度に複数の言語による実装を参照することができる、というメリットが学習用に有ります。
https://github.com/tokuhirom/HTML-Escape/blob/master/lib/HTML/Escape/PurePerl.pm
中心となるのは以下のコードです。
our %_escape_table = ( '&' => '&', '>' => '>', '<' => '<', q{"} => '"', q{'} => ''', q{`} => '`', '{' => '{', '}' => '}' );
sub escape_html {
my $str = shift;
return ''
unless defined $str;
$str =~ s/([&><"'`{}])/$_escape_table{$1}/ge;
return $str;
}
正規表現を使って、一気に変換していることが分かるでしょう。あらかじめ、ハッシュに変換パターンを用意しておき、正規表現の中からPerl変数を呼び出すことにより、全ての文字をまとめて変換をかける、というテクニックを使っています。この辺り、Perlの強力な正規表現をうまく使っていますね(eオプションを指定すると使える機能です)。
XS実装
次にXS実装を見てみます。
変換結果は同じですが、だいぶ様子が違います。
https://github.com/tokuhirom/HTML-Escape/blob/master/lib/HTML/Escape.xs
static const char unsafe[256] = {
/* 0 1 2 3 4 5 6 7 8 9 a b c d e f */
/* 0x00 .. 0x0f */ 0,0,0,0, 0,0,0,0, 0,0,0,0, 0,0,0,0,
/* 0x10 .. 0x1f */ 0,0,0,0, 0,0,0,0, 0,0,0,0, 0,0,0,0,
/* 0x20 .. 0x2f */ 0,0,1,0, 0,0,1,1, 0,0,0,0, 0,0,0,0,
/* 0x30 .. 0x3f */ 0,0,0,0, 0,0,0,0, 0,0,0,0, 1,0,1,0,
/* 0x40 .. 0x4f */ 0,0,0,0, 0,0,0,0, 0,0,0,0, 0,0,0,0,
/* 0x50 .. 0x5f */ 0,0,0,0, 0,0,0,0, 0,0,0,0, 0,0,0,0,
/* 0x60 .. 0x6f */ 1,0,0,0, 0,0,0,0, 0,0,0,0, 0,0,0,0,
/* 0x70 .. 0x7f */ 0,0,0,0, 0,0,0,0, 0,0,0,1, 0,1,0,0,
...
/* This is essentially a version of standard strcspn() that (a) handles
* arbitrary memory buffers, possibly containing \0 bytes, and (b) knows at
* compile-time which characters to detect, rather than having to build an
* internal data structure representing them on every call. */
static size_t safe_character_span(const char *start, const char *end) {
const char *cur = start;
while(cur != end) {
unsigned char c = (unsigned char) *cur;
if(unsafe[c]) {
break;
}
cur++;
}
return cur - start;
}
コンパイル時点でインデックスを作っておき、与えた文字列の中に対象があれば、一旦走査を中断して、置換とコピーを行い、再度走査を始める、という構成になっています。
while(cur != end) {
size_t span = safe_character_span(cur, end);
Copy(cur, d, span, char);
cur += span;
d += span;
if(cur != end) {
const char c = *(cur++);
if(c == '&') {
CopyToken("&", d);
}
else if(c == '<') {
CopyToken("<", d);
}
else if(c == '>') {
CopyToken(">", d);
}
実際に置換している文字は、(当たり前ですが)Pure Perl版と変わりません。
こうしてpure perlとXSで(当たり前ですが)、全然アプローチが違うのが面白いですね。
置換対象の文字について
と、書いてて気づいたのですが、よく見ると置換対象の文字が元記事のnpmモジュールと違いますね。
'{'、'}'、'`'の3文字が多い。
この差分は何でしょう?
調べて見ると、moznion氏が書いたC言語で書かれたHTMLのエスケープライブラリのコメントに良い情報がありました(これもまた違うアプローチで高速化されてて興味深いです)。
なるほど、これは知りませんでした、学びがありますね。
github.com
case '`':
memcpy(dst, "`", 5);
dst += 5;
break;
case '{':
memcpy(dst, "{", 6);
dst += 6;
break;
case '}':
memcpy(dst, "}", 6);
dst += 6;
break;
おわりに
HTMLエスケープはいろいろな手法が有る分野らしく、先程のmoznion氏のライブラリに関連して、こんな記事が有ることを思い出した。奥が深い。
mattn.kaoriya.net


")